
ETL in Big Data Architectures: Challenges, Tools, and Best Practices
By Nishanth Reddy Mandala, Software Engineer
Imagine a global e-commerce giant on Black Friday. Millions of customers are browsing, buying, and interacting with the platform simultaneously. To provide each customer with a personalized experience—recommending products, offering dynamic discounts, and ensuring smooth checkout—the company needs instant access to data. They need to know what’s trending, where inventory is running low, and how well promotional offers are performing. All of this depends on a robust ETL (Extract, Transform, Load) process capable of handling vast volumes of data in real time.
In this scenario, traditional ETL processes, which typically rely on overnight batch jobs, simply wouldn’t cut it. The company requires an ETL system that can manage big data and provide insights instantly. By leveraging modern ETL tools like Apache Kafka for real-time data streaming and Apache Spark for batch processing, the retailer can continuously collect, transform, and load data from various sources to drive intelligent decision-making throughout the day.
This real-world example highlights the importance of ETL in big data architectures, where data volume, variety, and speed are greater than ever. Let’s dive deeper into the role of ETL in big data, the unique challenges it faces, and the tools and best practices that make it effective.
The Role of ETL in Big Data Architectures
In big data contexts, ETL plays a critical role by making data from diverse sources accessible, clean, and ready for analysis. Unlike traditional ETL, which is typically batch-oriented, ETL in big data must manage much larger datasets, handle unstructured data, and often support real-time or near-real-time processing.
The ETL process in big data involves:
– Extracting data from multiple sources: This includes pulling data from transactional databases, social media feeds, IoT devices, logs, and other channels.
– Transforming data for consistency: Data is cleaned, aggregated, and structured for compatibility, ensuring it’s ready for analytics.
– Loading data into big data storage: Data is typically loaded into scalable storage systems like data lakes or distributed data stores such as Hadoop HDFS, or cloud data warehouses.
Challenges of ETL in Big Data Architectures
The demands of big data have introduced unique challenges for ETL processes:
- Scalability: Traditional ETL processes struggle to keep up with the sheer scale of big data. ETL tools in big data need to scale horizontally, allowing them to process massive datasets without performance degradation.
- Data Variety and Complexity: Big data ETL must handle structured, semi-structured (like JSON or XML), and unstructured data (like text or images). This diversity increases the complexity of transformations required to standardize the data.
- Latency and Real-Time Processing: In many big data applications, such as real-time fraud detection or personalized recommendations, processing needs to happen immediately. Batch ETL processes fall short here, making real-time ETL solutions essential.
- Data Quality and Consistency: With data flowing from many sources, ensuring accuracy and consistency is challenging. ETL processes must integrate data validation, cleansing, and deduplication to maintain quality across datasets.
- Cost Management: Processing large volumes of data, especially in real time, can be expensive, particularly in cloud environments. Optimizing ETL workflows to balance performance with cost is a key challenge in big data ETL.
Key Tools for Big Data ETL
To address these challenges, several tools and platforms have been developed specifically for ETL in big data architectures. These tools are designed to handle massive volumes, diverse data formats, and high-speed processing:
- Apache Spark: Known for its scalability, Spark supports ETL by enabling parallel processing across clusters, making it ideal for both real-time and batch ETL workflows.
- Apache Nifi: A tool designed for data flow automation, Apache NiFi simplifies ETL in big data by providing a visual interface for data flows and supporting real-time data integration from diverse sources.
- AWS Glue: Amazon’s fully managed ETL service, AWS Glue, automates ETL tasks and scales seamlessly with data volume, making it suitable for cloud-based big data environments.
- Google Dataflow: This serverless ETL service from Google processes real-time and batch data. It integrates with other Google Cloud services, making it a flexible option for big data ETL pipelines.
- Talend Big Data Integration: Talend provides a visual interface for designing ETL workflows that can connect with Hadoop, Spark, and cloud platforms, simplifying ETL for big data while ensuring data quality.
- Databricks: Built on Apache Spark, Databricks supports ETL, data science, and machine learning in a unified environment, making it well-suited for big data transformation.
Best Practices for ETL in Big Data Architectures
Handling big data in ETL workflows requires following best practices to improve performance, maintain data quality, and manage costs:
- Use Distributed Processing: To process large datasets effectively, leverage distributed frameworks like Spark and Hadoop that can handle data in parallel across clusters.
- Optimize Data Storage: Use scalable storage solutions like data lakes (e.g., Amazon S3) or distributed file systems (e.g., HDFS) to handle unstructured data and manage costs.
- Implement Real-Time Data Processing: For applications requiring real-time insights, use streaming ETL solutions such as Apache Kafka or Google Dataflow, which allow for continuous data ingestion and transformation.
- Ensure Data Quality: Incorporate data validation, deduplication, and cleansing into ETL workflows to maintain consistent and accurate data across all sources.
- Monitor Resource Usage and Costs: To control costs, especially on cloud platforms, optimize compute resources, and scale up only when needed. Serverless options like AWS Glue can help reduce idle time.
- Utilize Automation and Orchestration Tools: Tools like Apache Airflow or AWS Step Functions automate and manage ETL workflows, improving efficiency and reducing human errors.
Real-World Example Revisited: ETL in Retail Big Data
Returning to our e-commerce example, the retailer uses a combination of Apache Kafka for real-time streaming and Apache Spark for batch processing to manage data from diverse sources, including website logs, transactions, and social media. Real-time ETL allows them to monitor trends, adjust inventory, and make on-the-fly decisions during high-traffic events like Black Friday.
By implementing a hybrid ETL approach—combining real-time and batch processing—the company can respond to customer needs in real-time, enhancing the shopping experience and maximizing sales opportunities.
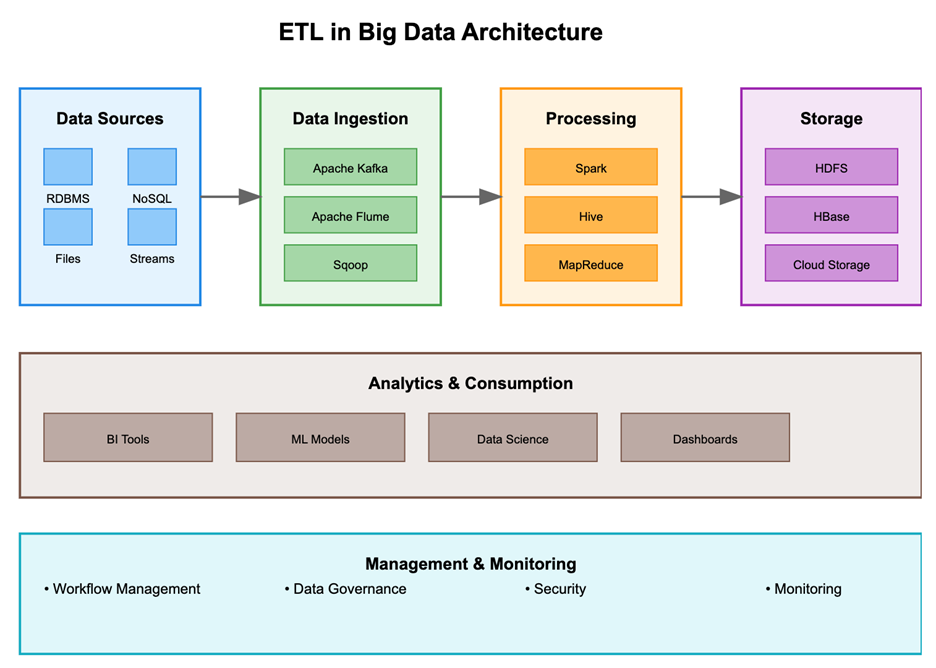
The figure illustrates the ETL (Extract, Transform, Load) workflow within a Big Data Architecture, highlighting the different stages and tools involved in processing and managing vast datasets. This architecture is designed to support the complexity, volume, and velocity of big data, enabling efficient data ingestion, transformation, and storage for analytics.
- Data Sources: The architecture begins with data sources, which may include relational databases (RDBMS), NoSQL databases, files, and streaming data. These diverse sources reflect the variety of data types that big data systems must handle, ranging from structured database records to real-time streams from IoT devices.
- Data Ingestion: Data from these sources is ingested using tools like Apache Kafka, Apache Flume, and Sqoop. Kafka and Flume are particularly effective for streaming data ingestion, allowing data to flow continuously into the ETL pipeline, while Sqoop facilitates the transfer of large volumes of data from relational databases into big data environments.
- Processing: In this stage, data transformation takes place using big data processing tools such as Apache Spark, Hive, and MapReduce. Spark is well-suited for parallel processing and handling complex transformations across distributed datasets, while Hive and MapReduce provide query and batch processing capabilities.
- Storage: Transformed data is stored in big data storage systems, such as HDFS (Hadoop Distributed File System), HBase for real-time reads and writes, or cloud storage solutions. These storage systems are designed for scalability, enabling the handling of petabytes of data and supporting fast data retrieval.
- Analytics & Consumption: The processed data is then accessible for various analytics and consumption applications. This layer includes BI Tools, Machine Learning Models, Data Science tools, and Dashboards that provide insights and visualizations to business users, analysts, and data scientists.
- Management & Monitoring: To maintain an effective ETL pipeline, workflow management, data governance, security, and monitoring are essential. These components ensure that data is managed properly, access is secure, and system performance is optimized.
Conclusion
ETL plays a crucial role in big data architectures, enabling organizations to process, transform, and load vast amounts of data efficiently. From managing diverse data sources to handling real-time insights, modern ETL tools and techniques have transformed the way data is integrated and prepared for analysis. As businesses continue to rely on data to drive decisions, ETL will remain a foundational element of big data ecosystems, adapting to new technologies and ensuring data-driven success.
Nishanth Reddy Mandala
Software Engineer
Nishanth Reddy Mandala is an experienced Data Engineer specializing in the retail and healthcare domains. With a strong background in building and optimizing data pipelines, he has developed a robust skill set across various ETL and cloud platforms. Nishanth excels in transforming raw data into actionable insights, enabling organizations to make data-driven decisions that enhance operational efficiency and customer experience. Known for his ability to tackle complex data challenges, Nishanth is passionate about leveraging technology to drive innovation and support strategic objectives in data-centric environments

